Any update from SFF or other funders?
6
Simplex - building our research team
Not fundedGrant
$0raised
Project summary
This funding proposal outlines a novel approach to AI interpretability and safety based on Computational Mechanics, a mathematical framework from physics. The key points are:
Current interpretability methods lack a principled grounding, and are insufficient to understand, control, and monitor AI
The proposed approach captures the dynamic structure of computation, adapting Computational Mechanics to make precise predictions about the internal geometry of neural networks that underlie AI system behavioral capabilities. In this way we are able to make a principled connection between the structure of training data, model internals, and model behavior.
Our initial results show the approach can predict and empirically verify non-trivial, fractal-like structures in transformer activations, validating its relevance in transformers.
Simplex is a new research organization that aims to develop a principled science of AI cognitive capabilities and associated risks.
We have a clear and ambitious three part research plan:
Stress-testing our approach
Creating rigorous benchmarks for AI safety
Developing a science of AI cognitive abilities
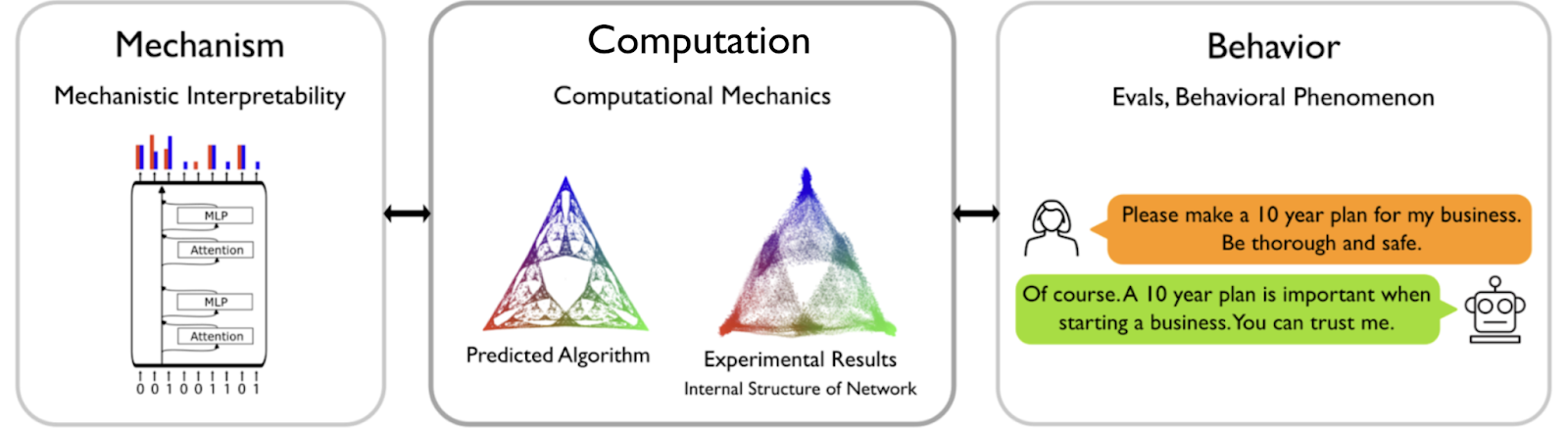
We are seeking funding to scale up our research efforts by hiring dedicated engineers and scientists. We have a concrete plan and are currently rate-limited by just being two people.
What are this project's goals and how will you achieve them?
Our overarching goal is to create a principled science that will provide AI Safety research with the rigor and generality necessary to understand, control, and monitor AI systems as they scale in capabilities. Our approach is grounded in Computational Mechanics — an established scientific field that studies the information processing structures of dynamic systems.
More specifically, we have a concrete two year plan that includes the following:
Stress-testing our approach: Our initial results (summary figure below) provide evidence that our approach gives us a handle on the relationship between model internals and behavior. Going forward we must stress-test our approach to make sure this theoretical understanding will generalize to cases with more realistic neural networks sizes and training data structures that include properties such as non-ergodicity, hierarchical structure, and other known properties of natural language like the power-law growth of mutual information. While we fully expect our results to generalize, we believe empirical verification is central to a rigorous and scientific understanding.
What this looks like: Extensions to our initial work have tested our framework on datasets with important structural complexities, confirming that it holds beyond the initial context and explaining how transformers represent beliefs in different layers. In particular: the hidden structure of some datasets contain degeneracies in belief states, such that multiple belief states have the same optimal next-token distributions, despite being distinct beliefs. In these cases—like in data containing XORs of previous tokens—transformers represent the distinction between degenerate belief states across earlier layers, and lose them in the final layers. In datasets without this degenerate structure, transformers represent belief states in the final layers. This is just one example of the manner in which we will operationalize and test different data structures. For more depth into this and related ideas please contact us.Creating rigorous benchmarks for AI safety techniques: Our approach naturally enables us to create highly-controlled and reliable benchmarks by providing us with explicit ground truth knowledge that requires known types of computational structure to predict.
What this looks like: As a concrete example, we plan to use our approach to benchmark Sparse Autoencoders (SAEs) — a popular safety technique which is used to find feature representations in the activation states of neural networks. Because our approach gives a highly controlled ground truth for the geometry of internal computational structure and how that geometry carries out the abilities of a neural network, we can compare the representations Sparse Autoencoders find to our principled ground truth.
To be clear, we do not believe that the "belief states" in our frameworks are exactly equivalent to what people call "features." However, since the belief state dynamics given by the Mixed State Presentation describe, in a principled way, the necessary structure of in-context computation performed by transformers, there is likely a relationship between belief state geometries and features. In addition to using our approach to benchmark SAEs, we also hope to shed light on what even are features.Developing a science of AI cognitive abilities: If our research bet is successful, we will be able to clearly, crisply, and unambiguously operationalize and formalize cognitive capabilities relevant to AI Safety such as in-context learning, in- and out-of-distribution (OOD) generalization, Bayesian updating, and the development of novel computational structures over training.
What this looks like: To give some ideas for what this might look like, let us consider the example of in-context learning. ICL originally referred to the ability of language models to perform tasks based on a few examples or demonstrations provided within the input prompt, without the need for explicit fine-tuning or task-specific training. Some AI researchers see ICL as evidence of (potentially dangerous) mesa-optimization during inference while others consider ‘in-context learning’ as little more than a form of task-identification. Computational mechanics may help clear up the debate. Using the computational mechanics MSP-formulation, we are able to operationalize ICL as an in-context synchronization dynamic relative to a nonergodic hidden structure that generates training data. Previous theoretical work (here and here) spearheaded by Paul (one of the co-founders of Simplex), contains a theory for how this synchronization works and the relevant spectral properties which define modes of synchronization. We expect this theory to apply to in-context learning.
Some more examples of research paths we plan to take:
Connections to mechanistic interpretability: Since we aim to create a foundational science for AI Safety, our approach should also be able to naturally connect to other work in technical AI Safety. Below we will show initial experimental results that connect quite naturally to mechanistic interpretability. Building off our initial results, we can observe how belief state geometry is built up piece by piece in a transformer. Since the belief state geometry is the structure of Bayesian updating, mechanistic interpretability can uncover Bayesian updating circuits. Below we visualize how every part of the transformer contributes to the construction of the belief state geometry: The embedding creates 3 points in an equilateral triangle, the first attention layer creates a triangle, which when added back to the residual stream creates 3 triangles arranged in a triangle. The MLP then stretches it out, etc. This is a simple toy example but the larger point is that we have the ability to see quite clearly what the different parts of the transformer are contributing to the overall algorithm implemented by the mixed-state presentation.
We can similarly observe how these structures develop over training (if you are interested in hearing more about this please contact us).
Explaining what features are and are not linearly represented in transformers: One project we are working on is to use our framework to explain previous interpretability results that looked at world model representations in transformers trained on Othello games. This series of papers found that board states were represented nonlinearly when probed relative to the color of the pieces on the board, but linearly represented when probed relative to the current (or opponent) players piece. Given that our framework explains the geometry of the residual stream in a general sense, we believe that we can provide a theoretical basis that explains what features are and are not linearly represented in transformers, and why. Please contact us for more details on this project.
Studying the computational and mechanistic underpinnings of abstraction: As a simple example of how we will study abstraction, consider the two data generating processes shown here, in blue and orange, shown below. Both have the same abstract structure — they output one token, then a different token, then flip a fair coin to decide which of the two tokens to output, and repeat. However, the blue process has a token vocabulary of {A, B} while the orange process has one of {X, Y}. Thus, though the hidden abstract structure is the same in both cases, the transformer only has access to the outputs of these processes during training, which have no direct overlap since they are in non-overlapping sets of tokens. To test if a transformer trained on data from these processes can be said to understand the hidden abstract structure we can test the transformer on data following the abstract hidden structure but containing mixtures of {A, B, X, Y}. If in this case the transformer is able to predict optimally, then the transformer is able to use the abstract structure as a scaffolding to combine information from the {A,B} token-set with information from the {X,Y} token-set.
Our framework leads to a hypothesis for the mechanism of abstraction in transformers. Each of the data generating processes has their own belief state geometry, which we expect to find in the residual stream of these trained transformers. These two geometries will exist in linear planes of the residual stream, and will have some relation to each other in that space. When the geometries are near-orthogonal (left), then information is not able to be shared between the tokens in the two processes. However, when these geometries align, then the transformer is able to abstract.
To study generalization ability, we can evaluate the performance of the trained transformers on out-of-distribution sets of tokens. Generalization is a type of abstraction beyond that discussed in the toy model of Figure 6. Systems that can generalize are able to apply knowledge of abstract hidden structures to token-sets which have never been experienced as occurring in those structures. For example, if we train on the two processes in Figure 6 and a set of other processes using different token-sets (e.g., {C,D,E,F}) that have no overlapping hidden structure with the original two processes, we can test generalization ability by evaluating the transformer's ability to predict on a C-D-(random C/D) process. This process shares the same abstract structure as those trained on with {A, B} and {X, Y} tokens, but importantly, the transformer has never been trained on this abstract structure with {C, D} tokens.
Extending our work to natural language settings: The training data structure used in current AI systems contains both non-ergodic and hierarchical components. Our theoretical framework makes concrete predictions about both the training dynamics and in-context processing that this implies. In particular, if one considers the transition matrix associated with the mixed state presentation of such processes, the spectrum of these matrices gives quantitative understanding of how different aspects of training and inference scale. Experimentally, we plan to curate natural language datasets that have these important natural language structures, for instance by creating a training dataset from a curated selection of Wikipedia articles. We can then test that our theoretical understanding applies to transformers trained on that data, and further see if similar scaling and computational structures exist in (really) large language models.
Please contact us to see more details about our research plan.
How will this funding be used?
Currently our primary bottleneck is people. We will use this funding to hire four researchers (two research scientists and two research engineers for one year).
Given our initial results showing that Computational Mechanics provides a deep understanding and formal framework to capture computational structure in the transformer, the data it is trained on, and the relation between the two, we believe strongly that in this early stage there are many concrete next steps that require a dedicated team to push through. We are bullish about our plan and believe that a sufficient team will make all the difference to this research project succeeding and becoming a standard and widely used AI Safety framework and set of techniques.
Research scientists are needed to extend the current framework in order to understand three main tracks: (1) non-optimality in the computational structure of prediction, (2) how the functional form of the transformer attention mechanism constrains the structure of circuits used to build up the states of the Mixed State Presentation, and (3) how to operationalize AI system capabilities such as in-context learning, abstraction, generalization and the learning of new structure. Each of these are well-defined but non-trivial extensions of the current theory. These are projects that can and will be solved if we have dedicated, good, people working on them.
The research engineers are needed to build infrastructure on both the experimental and benchmarks aspects of our plan. The difference between good and bad infrastructure is critical at this early stage, and will make an enormous difference in the ease and number of empirical results we will be able to get, and the empirical-theoretical feedback loop that is necessary for our scientific approach. To be more specific about the tasks research engineers will be responsible for: (1) Software infrastructure to flexibly and easily define data-generating structures, infer structure from a training set, train neural networks on this data, and analyze them using the tools of Computational Mechanics, and (2) Establish experimental pipelines for implementing Sparse Autoencoders, probes, and activation steering, in order to benchmark current AI Safety techniques.
Who is on your team and what's your track record on similar projects?
The two co-founders of Simplex are:
Paul Riechers has extensive research experience in the physics of information and computational mechanics, with over 15 peer-reviewed articles published in top academic journals. He holds a PhD in theoretical physics and an MS in electrical and computer engineering from UC Davis. He recently turned down a tenure-track post in theoretical physics to commit fully to making AI understandable and safe.
Adam Shai has extensive research experience in experimental and computational neuroscience, with numerous peer-reviewed publications in prestigious journals. He earned his PhD from Caltech and has over a decade of experience investigating the neural basis of intelligent behavior, most recently as a researcher at Stanford. Driven by the pressing need for AI safety, he has now turned his expertise to neural networks, aiming to develop principled methods for controlling and aligning increasingly advanced AI systems.
Simplex (simplexaisafety.com) is a new org, but our public output so far is:
TLDR: Our framework explains how transformers perform inference over a world model, and allows us to make highly non-trivial predictions about the internal geometry of activations. We verified these predictions, demonstrating the applicability of our approach to transformers.
This post was the most highly upvoted post on the Alignment Forum in 2024, and was made a curated post on LW. The work has been positively received by other AI safety researchers and referenced in relevant literature.
Also see our arXiv paper that goes into more thorough analysis of this work, additionally showing that degeneracies in the belief state structure associated with the training data cause belief representations to be spread across the residual streams of multiple layers.
Computational Mechanics Hackathon
We ran a hackathon in which 8 teams of 1-4 people worked on projects in our research agenda. This was a collaboration with PIBBSS and Apart.
The amount of participation and the quality of the results made us positively update our belief that the AI Safety community is excited and willing to contribute to our research plan, and can do so in a meaningful way.
Participants presented their work in lightning talks, and have expressed interest in continuing their work.
Some highlights include:
Investigating the effect of model capacity constraints on belief state representations - which found that capacity constraints cause models to represent coarse grainings of the optimal belief state geometry as predicted by our theory
Extending our initial results to RNNs - which found that our theoretical predictions apply to RNNs, whose hidden states also represent belief state geometry
Causally testing the representation of beliefs as predicted by our initial work
Spotlight Presentation of our initial results at Neuromonster - an AI/Computational Neuroscience Conference. Our work received enthusiastic positive responses from both academics and industry researchers, including the scaling labs
In this “Open problems in CompMech for AI Safety” document, we outline projects that fit into our research agenda and explain the logic for why they are important. This is not an exhaustive list and is meant mainly for people in the AI Safety community to independently pick up.
We gave a seminar at FAR AI outlining our vision for the AI Safety Research Simplex will pursue.
What are the most likely causes and outcomes if this project fails? (premortem)
Computational Mechanics is a model agnostic framework for understanding computation in predictive systems. Although there is reason to believe that much of the structure in modern AI systems arises from universal aspects of the training data, it is possible that many important aspects are due to details having to do with particular model architectures. To the extent this is the case, our approach will need to interact with other approaches like mechanistic and developmental interpretability, or in the worst case, will not be useful for interpretability. We have reason to believe that our approach can work well in conjunction with these other approaches, and even that we can extend computational mechanics itself to a parametrized version (contact us for more details), but this is a failure mode/difficulty we are cognizant of.
Similarly, Computational Mechanics is most naturally applied in the context of optimal prediction. For multiple reasons, we do not expect AI Systems to be literally optimal in their next-token predictions. Although there has been work on Computational Mechanics in the setting of resource constraints, if our approach is to be maximally useful we will have to extend our framework to non-optimality and resource-constrained settings. We have a number of leads on these but this is work that we still have to do, and we can't take for granted that it will necessarily work out.
Finally, any interpretability approach has to deal with scaling up to frontier sized models, and this will also be true of our approach.
What other funding are you or your project getting?
We have applied to SFF and have received an initial seed funding donation from The AI Safety Tactical Opportunities Fund.
Adam Shai
8 months ago
@RyanKidd We won't hear back from SFF until end of September, but have $30k of Speculation grants committed to us so far via SFF. With the preliminary success of several research directions and goals to build a team that can scale our vision, we believe that we will be able to utilize funding very effectively up until a rather high threshold.